
【导读】训大模型的方法可能要被革新了!AI大神Karpathy发布的新项目仅用1000行的C语言训完GPT-2.而不再依赖庞大的GPT-2库。他本人预告,即将上线新课。
断更近一个月,Karpathy终于上线了。
这次不是AI大课,而是带来一个新项目。
仅用1000行纯C语言训完GPT-2.
想象一下,如果我们能够不依赖于庞大的PyTorch(245MB)和cPython(107MB)库,仅仅使用纯C语言就能训练大型语言模型(LLM),那会怎样?
现在,借助llm.c,这件听起来似乎不太可能的事,已经成为了现实!
这个项目的亮点在于,它仅用约1000行简洁的C代码,就实现了在普通计算机处理器(CPU)上训练GPT-2模型的能力。
而且,这份代码不仅可以立即编译运行,其训练结果也和PyTorch版本的GPT-2完全一致。
之所以选择GPT-2作为起点,是因为它标志着大型语言模型发展史上的一个重要里程碑,是第一次以我们现在所熟悉的形式整合了这样的技术栈,并且模型权重也是公开可获取的。
这一项目刚刚发布几个小时,已经获得了2.5k星。

项目地址:https://github.com/karpathy/llm.c
有网友表示,初创公司正在等着Karpathy挖掘新的点子。
很少有人知道,SUNO一开始是nanoGPT的一个分支。(Suno创业团队首款产品Bark受到了nanoGPT的启发)


或许Karpathy正在尝试的是重新设计LLM架构,通过llm.c项目去探索一种更简单、高效的模型训练方法。


「我无法创造的,我就无法理解」。


Karpathy完全让AI走向大众化。

那么,仅用C语言如何训出LLM?
千行C代码训完GPT-2
项目开篇介绍中,Karpathy还提到了自己目前正在进行的研究:
- 直接使用CUDA实现,速度会快得多,可能接近PyTorch。
- 使用SIMD指令加速CPU版本,x86上的AVX2/ARM上的NEON(比如苹果芯片)。
- 采用更现代的架构,如Llama2、Gema等。
对于repo,Karpathy希望同时维护干净、简单的参考实现以及更优化的版本,这些版本可以接近PyTorch,但只需很少的代码和依赖项。
快速入门
下载数据集,并将其进行分词。Tinyshakepeare数据集下载和分词速度最快:
python prepro_tinyshakespeare.py
打印内容如下:
Saved 32768 tokens to data/tiny_shakespeare_val.bin
Saved 305260 tokens to data/tiny_shakespeare_train.bin
其中,.bin文件包含有int32的原始数据流,这些整数代表了通过GPT-2分词器定义的Token ID。
当然,也可以通过运行prepro_tinystories.py来对TinyStories数据集进行分词处理。
理论上讲,现在已经能够开始训练模型了。但是,目前基于CPU和FP32的参考代码运行效率极低,无法从零开始训练这些模型。
因此,我们选择先用OpenAI发布的GPT-2模型权重进行初始化,再对模型进行微调。
为了这个目的,我们需要下载GPT-2模型的权重文件,并把它们作为检查点保存下来,这样就可以在C语言环境中进行加载了:
python train_gpt2.py
这个脚本的作用是下载GPT-2(124M)模型,并对单个数据batch进行10次迭代训练实现过拟合。
接着,脚本将执行几步生成任务,并且最重要的是,保存两个文件:
gpt2_124M.bin,其中包含了可用于在C语言环境中加载模型的原始权重;
gpt2_124M_debug_state.bin,其中包含了额外的调试信息,如输入数据、目标、logits和损失。
这些信息对于调试、单元测试以及确保与PyTorch的参考实现完全一致很有帮助。
目前,主要关注的是gpt2_124M.bin文件中的模型权重。有了它们,就可以在C语言环境中初始化模型并开始训练了。
首先,我们需要编译代码:
make train_gpt2
你可以打开Makefile文件,并阅读里面的注释。
它会自动检查你的电脑是否支持OpenMP,这对于以非常低的复杂度来加速代码运行很有帮助。
当完成train_gpt2的编译之后,就可以开始运行了:
OMP_NUM_THREADS=8 ./train_gpt2
现在,你需要根据电脑的CPU核心数来设置程序运行的线程数。
然后,程序会加载模型的权重和Token,接着进行几次迭代的微调过程,这个过程使用了Adam优化算法,学习率设置为0.0001.
最后,程序会根据模型生成一个样本。
总结来说,代码实现了模型每一层的数据处理流程,包括前向传播、反向传播和参数更新等,并且被组织成了一个完整的循环。
目前,程序生成的结果只是Token ID,我们需要把这些编号转换成可读的文本。
这个过程在C语言中实现起来相当简单,因为涉及到的主要是对应字符串片段的查找和输出。
现在,我们可以利用一个叫做tiktoken的工具来完成这个任务:
Karpathy表示,他对Netflix在模型生成结果中的呈现方式非常满意,因为这显示出模型仍然保留了其训练过程中的一些特征。
此外,他也没有去调整微调的超参数,因此如果能够优化这些设置,特别是通过延长训练时间,模型的性能应该会有很大的提升空间。
测试
这里提供一个简单的单元测试程序,用来验证我们编写的C语言代码是否与PyTorch框架中的代码实现相匹配。
通过以下命令即可编译并执行:
make test_gpt2
./test_gpt2
这段代码首先会加载gpt2_124M_debug_state.bin文件,然后执行一次前向计算。
这个过程会生成模型的预测结果(logits)和损失(loss),并将其与PyTorch的标准实现进行比较。
接下来,它会利用Adam优化算法对模型进行10轮训练,从而确保训练的损失与PyTorch的结果一致。
教程
项目最后,Karpathy还附上了一个非常小的教程——

它是实现GPT-2模型的单层,即LayerNorm的一个简单的分步指南。
这是了解如何用C语言实现层的一个很好的起点。
纯CUDA也可训
在训练开始时,先一次性预分配一大块一维内存,用于存储训练过程中所需的所有数据。
这样做的好处是,在整个训练过程中,我们无需再次分配或释放内存。如此一来,不仅简化了内存管理,还确保了内存使用量保持不变,优化了数据处理效率。
接下来的核心任务是——手动编写代码,实现模型中每一层的数据前向传播和后向传播过程,并将这些层按顺序连接起来。
此外,为了构建完整的模型,我们还需要实现多个关键组件,包括编码器(encoder)、矩阵乘法(matmul)、自注意力机制(self-attention)、GELU激活函数、残差连接(residual)、softmax函数和交叉熵损失计算。

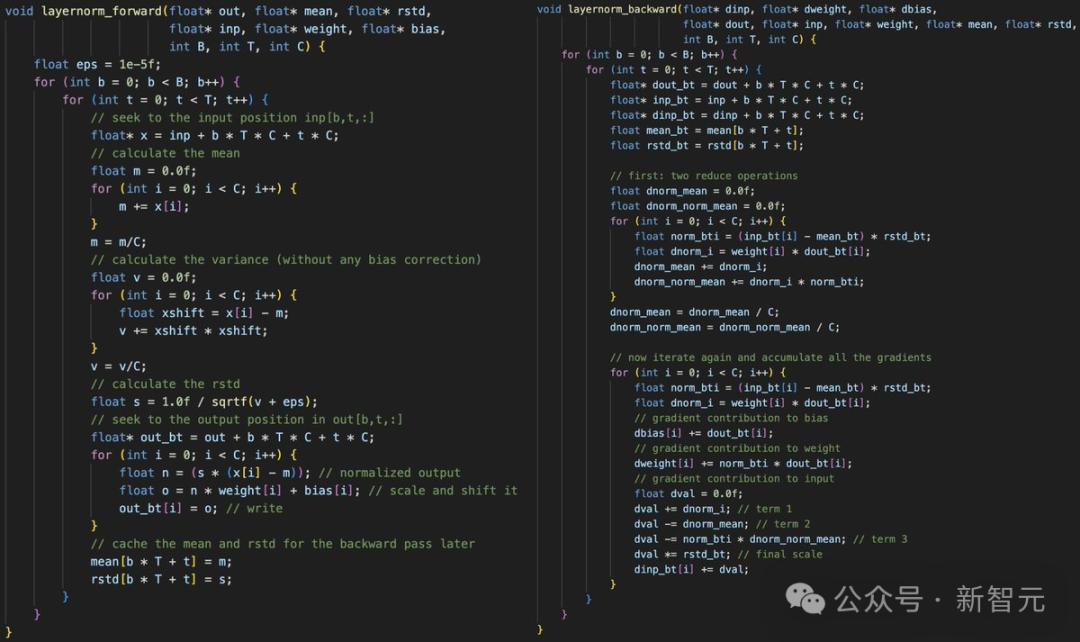
Karpathy继续解释道,一旦你有了所有的层,你就可以把所有的层串联起来。
不瞒你说,写这个过程相当乏味,也很受虐,因为你必须确保所有的指针和张量偏移向量都正确排列。

左图:在内存中分配一个一维数组,然后将所有模型的权重和激活指向它
右图:小心地进行所有指针运算
在完成了模型的前向传播和反向传播之后,接下来的工作,比如设置数据加载器和调整Adam优化算法,就比较简单了。
随后,Karpathy还介绍了自己下一步进行工作是:
一步步地将这个过程迁移到CUDA上,从而大幅提升运算效率,甚至达到接近PyTorch的水平,而且不需要依赖那些复杂的库。
目前,他已经完成了其中的几层。
接下来的工作包括减少计算精度——从FP32降到FP16甚至更低,以及添加一些新的层(如RoPE),从而支持更先进的模型架构,例如Llama 2、Mistral、Gemma等。
当然了,等着这一切完成之后,另一期「从头开始构建」的视频也会上线。